It is designed to work with search engines, but surprisingly it is a source of SEO juice that is just waiting to be unlocked.
I have seen the client bend over the backward people to increase their SEO. When I tell them that they can edit a small text file, they almost do not believe me.
However, there are several ways to increase SEO that are not difficult or time-consuming, and it is one of them.
You do not have to have any technical experience to take advantage of Robots.txt power. If you can find the source code for your website, you can use it.
First of all, let’s take a look at why a robots.txt file matters in the first place.
The Robots.txt file, also known as the Robot Exclusion Protocol or Standard, is a text file that tells web robots (often search engines) to crawl your site.
It also tells web robots what pages do not have to crawl.
Assume that the search engine is about to visit a site. Before going to the goal page, it will check the robots.txt for instructions.
This is the original skeleton of a robots.txt file.
After a “user-agent” asterisk means that the robots.txt file applies to all web robots coming to the site.
After “Disapproved”, the slash tells the robot not to go to any page on the site.
After all, one of the main goals of SEO is to get a search engine to easily crawl your site so that they increase your ranking.
This is where the secret of this SEO hack comes from.
Possibly many pages on your site, right? Even if you do not think you do, check it out. You might be surprised.
If a search engine crawls your site, it will crawl every page of your site.
And if you have a lot of pages, they will take a short time to crawl search engine bots, which can have a negative impact on your ranking.
Because Googlebot (Google’s search engine bot) has “crawl budget”.
You want to help Googlebot spend your crawl budget best for your site. In other words, it should crawl your most valuable pages.
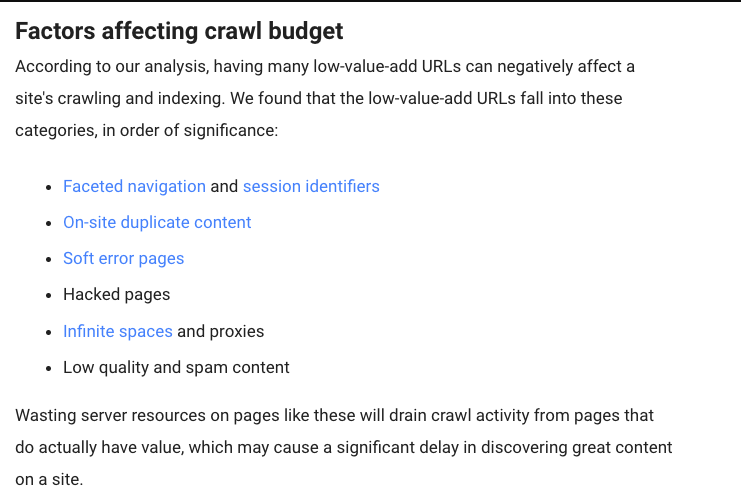
According to Google, there are some factors, which “negatively affect a site’s crawling and indexing.”
So let’s go back to robots.txt.
If you create the right robots.txt page, you can tell search engine bots (and specifically Googlebot) to avoid some pages.
Think about the implications. If you call search engine bots just to track your most useful content, the bots will crawl and index your site based on that content only.
“You do not want to overwhelm your server with Google’s crawler or you want to ruin the crawl budget on unimportant or similar pages on your site.”
By using your robots.txt file correctly, you can ask search engine robots to spend their tracking budget intelligently. And that makes the SEO.txt file so useful in terms of SEO.
Inspired by the power of robots.txt?
You must be! Let’s talk about how to find it and how to use it.
If you want to see your robots.txt file right away, it’s an easy way to look at.
In fact, this method will work for any site. That’s why you can see files from other sites and see what they are doing.
One of three situations would be:
1) You will find a robots.txt file.
2) You will get an empty file.
Take a second time and look at your site’s robots.txt file.
If you get an empty file or 404, then you want to fix it.
If you do not find a valid file, it’s probably set to the default settings that were created when creating your site.
I like this method especially to see the robots.txt files of other sites. Once you learn the ins and outs of robots.txt, then this can be a valuable exercise.
All your next steps will depend on whether or not you have a robots.txt file or not. (If you check using the method described above.)
If you do not have a robots.txt file, you will need to create one with scratch. Open a plain text editor like Notepad (Windows) or TextEdit (MAC).
Use only a plain text editor for this. If you use programs like Microsoft Word, then the program can insert additional code in the text.
Editpad.org is a great free option, and you use it in this article.
Back to robots.txt If you have a robots.txt file, you have to find it in the root directory of your site.
If you did not panic around the source code, then finding an editable version of your robots.txt file can be a bit tricky.
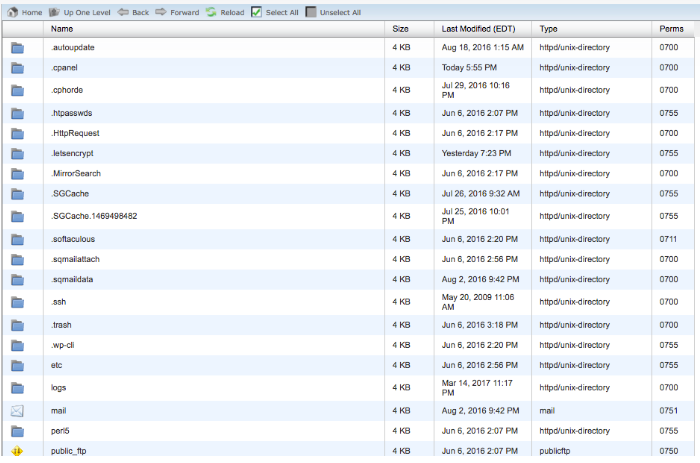
Typically, you can go to your hosting account’s website, enter your site’s file management or FTP section, and find your original directory.
You should look something like this:
Find your robots.txt file and open it for editing. Delete all the text, but keep the file.
If this happens to you, you will need to create a new robots.txt file.
You can create a new robots.txt file using the plain text editor of your choice. (Remember, use only a plain text editor.)
If you already have a robots.txt file, make sure that you’ve removed the text (but not the file).
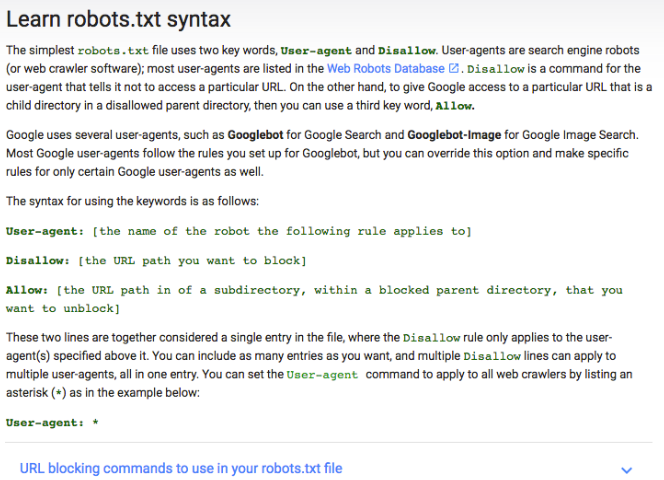
First of all, you need to be familiar with some of the syntax used in the robots.txt file.
I am going to show you how to establish a simple robot.
Start by setting user-agent word We’re going to set it up so that it’s applicable to all web robots.
Do this by using the asterisk after the word user-agent, such as:
Next, type “reject”, but do not type anything after that.
Since there is nothing after the rejection, the web robot will be directed to crawl your whole site. Right now, everything on your site is a good game.
So far, your robots.txt file should look like this:
I know that it sounds super simple, but these two lines are already doing a lot.
Believe it or not, it looks like an original robots.txt file.
Now move it to the next level and turn this small file into a SEO booster.
How do you optimize robots.txt It all depends on the content on your site. There are all sorts of uses of robots.txt for your advantage.
I will go on some of the most common ways of using it.
(Keep in mind that you should not use robots.txt to block pages from search engines, this is a large number.)
One of the best uses of the robots.txt file is by notifying the search engine’s crawl budget that crawling those parts of your site that are not displayed to the public.
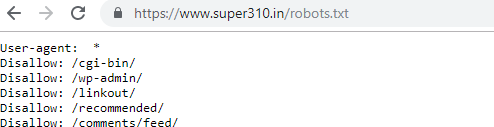
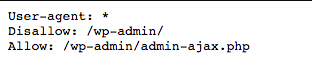
For example, if you go to a robots.txt file for this site (super310.in), you will see that it stops the login page (wp-admin).
Because that page is used to log into the backend of the site, so it will not be understood to waste time for search engine bots.
(If you have WordPress, you can use the same exact denial line).
You can use the same instructions (or command) to prevent bots from crawling specific pages. After disallow, enter the portion of the URL that comes after .com. Place between two forward slashes.
So if you do not want to crawl your page http://yoursite.com/page/, you can type it:
You might be thinking specifically what types of pages are excluded from indexation. Here are some common scenarios where this would be:
For example, if you have a printer-friendly version of a page, then you have technically duplicate content. In this situation, you can ask bots not to crawl one of those versions (usually a favorable version of the printer).
It’s also easy if you split-up pages that have the same content but different designs.
Thanks Page Thank You-U is one of the favorite pages of marketers because it means a new lead.
…right?
As it turns out, some thanks pages are accessible through Google. This means that people can access these pages without going through the lead capture process and this is bad news.
By blocking your thank you pages, you can ensure that only qualified leads are viewing them.
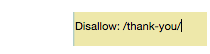
So, please visit your thank you page at https://yoursite.com/thank-you/. In your robots.txt file, blocking that page will look like this:
Since there are no universal rules to deny which page, your robots.txt file will be unique to your site. Use your decision here.
Do you know which instruction we are using? This does not really prevent the page from being indexed.
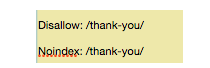
So you need a noindex instruction. Works with instructions to make sure the bots are not for viewing or indexing some pages.
If you have a page that you do not want to index (like a valuable thank you page), then you can use both a disapproved and noindex instruction:
Now, that page will not be displayed in SERPs.
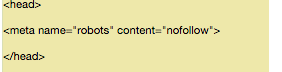
But the nofollow command is to be implemented in a different way because it is not actually part of the robots.txt file.
However, the nofollow instructions are still directing the web robot, so this is the same concept. The only difference is where it is. Where it is.
Find the source code of the page that you want to change, and make sure you are between the tag.
Make sure you are not putting this line between any other tags – only the tag.
This is another good choice of web pages thanks to that web robots do not crawl links for any lead magnets or other special content.
This web robot will give both instructions at once.
In the end, test your robots.txt file to make sure that all things work in a valid way.
Choose your property (i.e., website) and click on “crawl” in the left hand sidebar.
You will see “robots.txt tester”, click on it.
If “test” text changes to “allowed”, it means that your robots.txt is valid.
Finally, upload your robots.txt to your root directory (or if you already have it, save it there). Now you are equipped with a powerful file, and you should see an increase in your search visibility.
I always like to share a little known SEO “hack” which can give you real benefits in more than one way.
By setting your robots.txt correctly, you are not only boosting your own SEO. You are also helping your visitors.
If search engine bots can spend their crawl budget wisely, they will organize and display your content in SERPs the best, which means that you will be more visible.
Whether you are starting your first or fifth site, you can make a significant difference using robots.txt. If you have not done it before, then I recommend giving it a spin.
What is your experience creating robots.txt files?